



Haiku Repository Files and Identifiers
Software on a computing platform such as Haiku is typically distributed as a package. Without a packaging system it would be hard for users to install software and because software often depends on other software, the chain of dependencies would be difficult for a user to resolve themselves. To orchestrate the distribution and management of the packages, Haiku has a packaging system which consists of applications, online tools, on-host tools and software libraries. One aspect of the packaging system is the coordination and identification of repositories.
What is Stored in a Repository?
A repository is a collection of packages coupled with an index of those packages.
A repository could reside on any storage media. This is most conveniently a web-server, but could also be a DVD for example. It is simply a collection of files. The baseUrl is used to identify the transport mechanism and address used to access the repository data. The baseUrl is what users require to configure a repository on their Haiku system. By way of example, the baseUrl of HaikuPorts repository for the x86_64 computing architecture is;
https://eu.hpkg.haiku-os.org/haikuports/master/x86_64/current
The repository also contains a special file repo.info that describes the repository found at a given baseUrl. Here is an example of what this might look like;
name HaikuPorts
vendor "Haiku Project"
summary "The HaikuPorts repository"
priority 1
identifier e90b7d69-969c-4c26-8894-06f965818c7d
architecture x86_64
The repository also contains a file with a well known filename repo. This repo file is in an optimized Haiku-specific format called “HPKR” and it contains a catalog of all of the packages that are available in the repository as well as some meta-data about the files such as their copyrights, English-language summaries etc…
Finally the repository also contains the packages themselves. These files are in a directory packages with a leaf-name that includes the package name as well as the version and target computing architecture. For example;
armyknife-5.1.0-4-x86_64.hpkgartpaint-2.1.0git-7-x86_64.hpkg
These package files are conveyed in a different optimized Haiku-specific format called “HPKG”. This typically contains binaries to be executed on a Haiku system as well as resources such as images and documentation to support the software included in the package.
Where Do the Repository Data Files Go?
When a user registers a repository onto their Haiku system, the system will download the repo.info file and the repo HPKR file. By means of example, considerating the configuration of the HaikuPorts repository, the HPKR file is stored at…
/system/cache/package-repositories/HaikuPorts
…and the repo.info lands at…
/system/settings/package-repositories/HaikuPorts
Mirrors
A mirror is a copy of a repository at a different baseUrl. There are a number of reasons why a mirror is a good idea.
- A single server and its bandwidth may be exhausted by a large number of users accessing it at once.
- If a single server fails then it may impact a large number of users of the platform and a backup location would provide an alternative.`
- Users may be in very different geographies. For example, Germany and New Zealand are on the opposite sides of the planet. If a significant number of users from New Zealand access the repository in Germany then this would mean a potentially large volume of international internet traffic would unnecessarily traverse the globe. It is better if the traffic were contained in the Oceania region of the world where New Zealand is located because this would put less strain on international links and would also be faster for the New Zealand users.
The following diagram shows two mirrors servicing the x86_64 architecture in two different parts of the world.
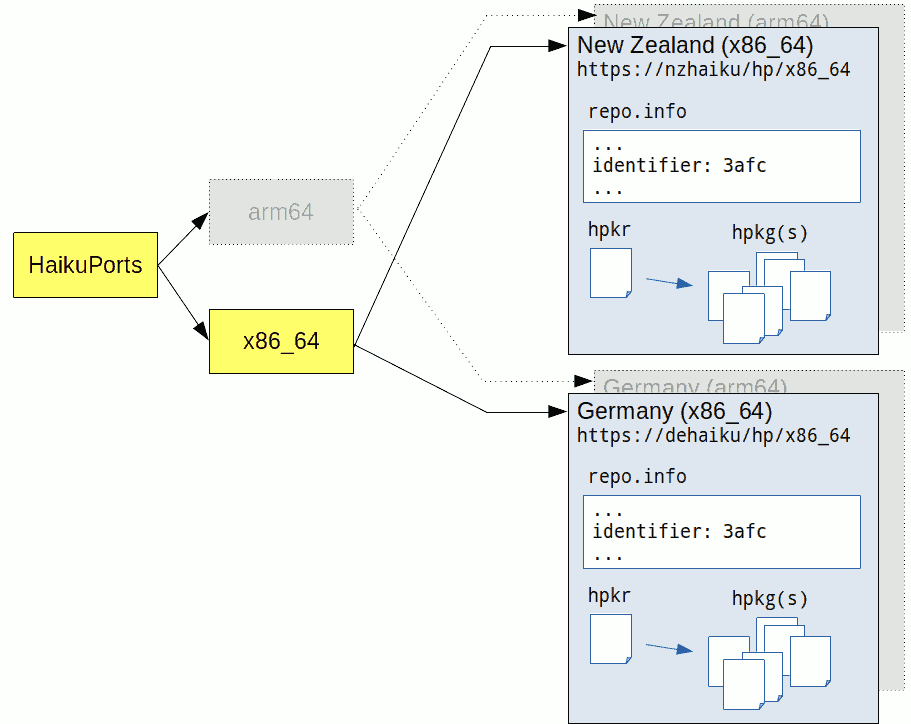
It is important to note that although the baseUrl is different for accessing the two repositories (one URL for New Zealand and another for Germany), the identifier found in the repo.info file is exactly the same. Regardless of how the logical repository is accessed, the repository is considered to be the same if the identifier is actually the same.
It is also worth noting that the repository may or may not exist for different computing architectures. For each architecture there will be a different identifier because each architecture represents different packages and a hence a different repository.
Haiku Depot and Haiku Depot Server
HaikuDepot is a desktop application for the Haiku system that allows end users to browse and search for packages as well as ultimately install them.
Through the PackageKit library, HaikuDepot reads the cached repo (HPKR) file originally sourced from the remote repository and uses this to obtain information about which packages would be available in the repository as well as meta-data about the packages to show in the user interface.
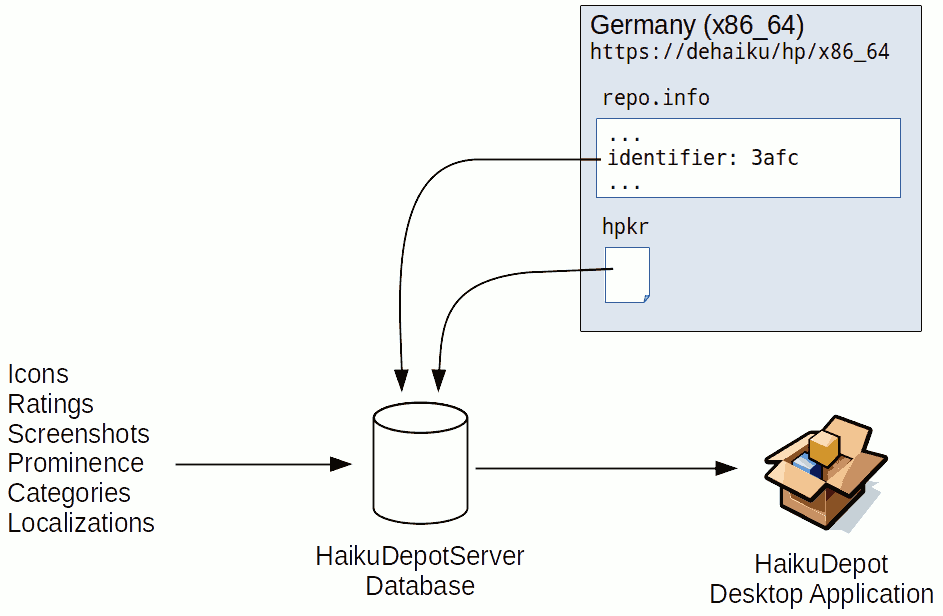
Some data however is not transported in the HPKR file. The following image shows some elements that are not conveyed in the HPKR and instead come from an internet application called HaikuDepotServer (HDS).
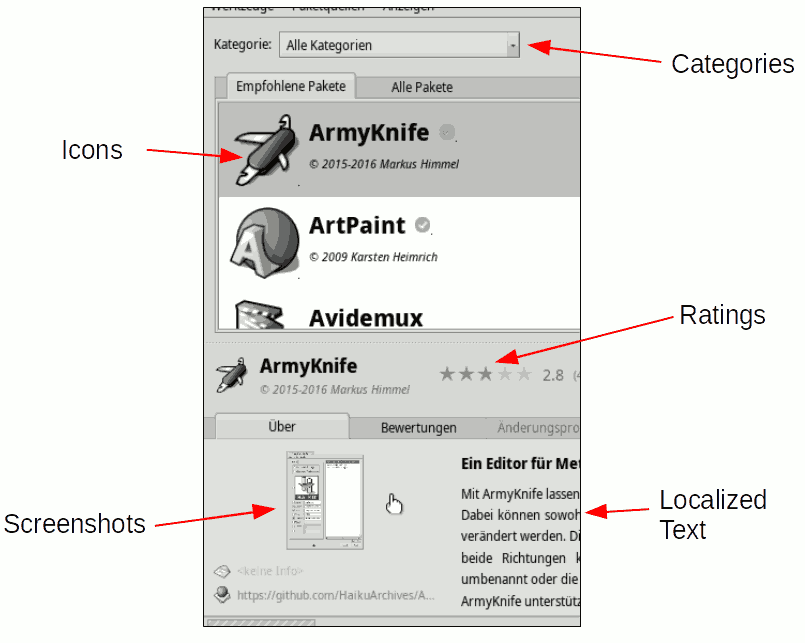
HDS provides a user-interface that is a curation system for this community-supplied data and also distributes the collated data to the users who are running HaikuDepot so that the information can be displayed in the desktop application’s user interface.
Closing the Loop with the Identifiers
HDS will periodically download the repo.info and repo file from the repository and parse them into its own database. When it later provides the repository data to the HaikuDepot desktop application, HDS includes the identifier for each repository. HaikuDepot is then able to correlate the identifier coming from HDS with the identifier available from its local cache of the repo.info file. This way HaikuDepot is able to ascertain which repository or repositories to observe in HDS in relation to the locally configured repositories regardless of which mirror was used.
HaikuDepot is able to show a list of packages from the locally configured repositories and is also able to enhance the available data locally with the packages' data stored in HDS.
Beta Releases
Sometimes it is necessary for an actual repository configured on a Haiku system to correlate with the “wrong” repository in HDS; in other words the identifier values do not match.
An example is a beta release. In this case, it is desirable for the beta release repository’s identifier to be different to distinguish it, but at the same time, it is desirable that the packages' meta-data are blended with the regular repository in HDS. In this case, HDS also supports a repository having some fake identifier values that HD will also honour.
Summary
This article explains what files and identifiers exist in the larger Haiku repository system so that data is able to flow through the various applications correctly.
