 |
|
| |
 Displaying Newsletter
Displaying Newsletter
|
| Issue 44, 18 Jun 2003
|
|
|
|
|
|
|
Howdy. This is the first issue of the OpenBeOS CVS digest. The idea of having a digest of all the CVS commits done in a certain period of time comes from
Derek Kite, who has done a similar thing for the KDE CVS.
However, the arrangement and the style of this digest is somewhat different from the one of Derek Kite.
This CVS digest contains a selection of commits from the sixth of June onward (just after the release of the Media Kit alpha 1). Please note that there are more things done to the CVS repository. If you would like a better overview of the changes in the repository, please look at the
archives of the OpenBeOS-CVS list, or subscribe
. Now, let's get on with the changes.
Screen Preflet
On the 6th of June, Stefano Ceccherini committed, by means of Marc Flerackers, a major change to the Screen Preflet:
Modified Files:AlertView.cpp AlertView.h AlertWindow.cpp AlertWindow.h Constants.h RefreshSlider.cpp RefreshSlider.h RefreshView.cpp RefreshView.h RefreshWindow.cpp Screen.cpp Screen.rsrc ScreenApplication.h ScreenDrawView.cpp ScreenDrawView.h ScreenSettings.h ScreenView.cpp ScreenView.h ScreenWindow.cpp ScreenWindow.h Utility.cpp Utility.h
Log Message:Check-in for Stefano Ceccherini: cleanup the code a bit, removed the hardcode color
But on the ninth of June, Stefano found out he had forgotten something, and he added:
Modified Files:ScreenDrawView.cpp ScreenDrawView.h ScreenWindow.cpp ScreenWindow.h
Log Message:When you changed the refresh rate for all workspaces, then selected "cancel" the changes didn't revert... Fixed. Some more cleanups. Some code (not compiled right now, it works partially) to change the way the example screen is rendered (bitmaps instead of drawing)
Check the source of the Screen Preflet to see the result of these commits and some other changes!
Media Kit Alpha 1 and onward
J�r�me Duval committed a change to the SoundPlayer class, which allows applications to change the volume now. On the sixth of June, the following happened:
Modified Files:SoundPlayer.cpp
Log Message:ok the right file this time ... *Volume* methods implemented; tested with SoundPlayerTest.cpp; only valid when connected with R5 AudioMixer
As promised by Marcus Overhagen, the new mixer for the Media Kit alpha 2 was already worked on. On the sixth of June he committed this:
Modified Files:Jamfile
Added Files:MixerCore.cpp
MixerCore.h
MixerInput.cpp
MixerInput.h
MixerOutput.cpp
MixerOutput.h
Log Message:added new mixer components
On the tenth of June, Axel D�rfler, who seems to be involved with literally every part of the codebase, committed a change to the ParameterWeb class of the media kit:
Modified Files:ParameterWeb.cpp
Log Message:Work in progress of the BParameterWeb rework; almost every line has been changed, sorry. Fixed many bugs in the old implementation, this one is now also endian-aware, is faster on many things, works with stampTV, ... Cleaned up a lot, most of it now complies with our style guide. Added a bunch of helper functions that makes the code much better (to read), and easier to maintain. It's not yet completed though - will do that soon. Also still missing is any documentation about those classes - I will also work on this. The changes have two downsides, though:
- I broke compatibility with the R5 flattened format. It shouldn't be a big issue, since it was never thought to be put on disk - I will look into that, though.
- the previous implementation had a strange policy when the Unflatten() methods had reason to fail - it tried to read as much as possible instead of just failing and leaving an invalid object behind. The new implementation will just fail - the object you called Unflatten() from might not contain useful information after this, though.
If you are wondering, like me, what this ParameterWeb does, check out the following answer Axel gave me when I asked him:
It contains all the parameters that a controllable node exposes - all gui you see from any media stuff is based on that data.
And Marcus Overhagen added that it seems to work now!
The same Marcus Overhagen, on the eleventh of June, continued work on the mixer. All in all a great amount of work is done on this very important kit. So the media kit is also progressing nicely.
Disk Device Manager
Ingo Weinhold on the ninth of June:
Added Files:KDiskDevice.h KDiskDeviceJob.h KDiskDeviceJobFactory.h KDiskDeviceJobQueue.h KDiskDeviceManager.h KDiskSystem.h KFileSystem.h KPartition.h KPartitioningSystem.h ddm_modules.h ddm_userland_interface.h disk_device_manager.h
Log Message:Headers for the disk device manager. Very early state.
And he continued that same day with:
Added Files:List.h KDiskDevice.cpp KDiskDeviceJob.cpp KDiskDeviceJobFactory.cpp KDiskDeviceJobQueue.cpp KDiskDeviceManager.cpp KDiskSystem.cpp KFileSystem.cpp KPartition.cpp KPartitioningSystem.cpp disk_device_manager.cpp Jamfile
Log Message:Mostly empty implementations for the disk device manager classes. Save KPartition which is partially done.
He continued his line of empty implementations with:
Added Files:KCreateChildJob.h KDefragmentJob.h KDeleteChildJob.h KInitializeJob.h KMoveJob.h KRepairJob.h KResizeJob.h KScanPartitionJob.h KSetParametersJob.h KCreateChildJob.cpp KDefragmentJob.cpp KDeleteChildJob.cpp KInitializeJob.cpp KMoveJob.cpp KRepairJob.cpp KResizeJob.cpp KScanPartitionJob.cpp KSetParametersJob.cpp
Log Message:Mostly empty implementations for the disk device manager classes. Save KPartition which is partially done.
Slowly but surely the empty implementations are replaced with bits of working code. For example on the tenth of June with:
Modified Files:KDiskDeviceManager.cpp
Log Message:Implemented some basics of KDiskDeviceManager.
On the thirteenth of June, another milestone was reached with the porting of the Intel partition type, to the new kernel module:
Added Files:Jamfile
PartitionMap.cpp
PartitionMap.h
intel.cpp
Log Message:Ported the intel partitioning system module to the new interfac (disk device manager) and moved it to a nicer place. First tests look good, though my hard disk structure doesn't even have extended partitions. Going to install Linux now...
Slowly but surely the empty implementations are replaced with some real code. Are you wondering what the use of this code is? The Disk Device API is a way for the programmers to find out which logical volumes are present on the system. Ingo Weinhold first wanted to implement this in user space, but apparently he has chosen the kernel space after all. If you want to check out the current progress, visit the
source and the
headers
in the webcvs.
Bits'n'Pieces
On the eight of June, Jack Burton by means of Axel D�rfler, committed some cleanups:
Modified Files:digit.c
null.c
zero.c
Log Message:Some cleanups, courtesy of Jack Burton.
On the eleventh of June, Bill Hayden had an enlightenment and did some work on the statusbar:
Modified Files:StatusBar.cpp
Log Message:Conform more tightly with the BeBook, and fix a few crashing bugs in the process
Darkwyrm added, on that same day, the following to CVS:
Log Message:Added rcs
, gzip, sed
, and associated utilities.
Andrew Bachman, following the release of Pulse 1.06, added some CPU types on the thirteenth of June:
Modified Files:OS.h
Log Message:okay, last commit for today :-P ... protected non-R5 cpu types with #define OBOS_CPU_TYPES and #ifdef OBOS_CPU_TYPES
That same day, Niels Reedijk (hey, that's me!), by means of Philippe Houdoin, committed a new (experimental!) Realtek 8193 driver to the CVS:
Added Files:Jamfile TODO driver.c ether_driver.h packetlist.c packetlist.h util.c util.h
Log Message:Import, on behalf of Niels Reedijk (SF ID: nielx), his RTL8139 network cards driver. Add a Jamfile to build it (thanks to Axel's sis900 jamfile).
A minor note: the driver drops half the packets at the moment. If you want to try the source
, please mail me personally to also get the source of the net_server add-on.
On the fifteenth of June Axel D�rfler committed an update to the driver_settings module in the kernel with the following message:
Added Files:driver_settings.c
Log Message:This replaces kernel/core/driver_settings.c - its functionality will now be available to userland applications as well. Furthermore, the API & grammar has been extended. There is now a '=' allowed between the key and its values. Also, '\n' can now be replaced with ''. These changes allow flat driver_settings strings. It doesn't work perfectly right now, but it's a start. A test application will be added soon, the kernel file will be removed soon as well, and the build updated.
|
|
|
|
Axel recently asked me about what sort of a plan I had for file caching. I realized that I couldn't easily explain it without explaining a significant portion of VM2 design, so I started to write this up. As I did so, I realized that others may be interested. So, without further ado, here we go...
Be's file caching is pretty simple, by all reports. On startup, the file system looks to see how much ram your machine has. It then allocates a portion of that for file system cache--about 1/8
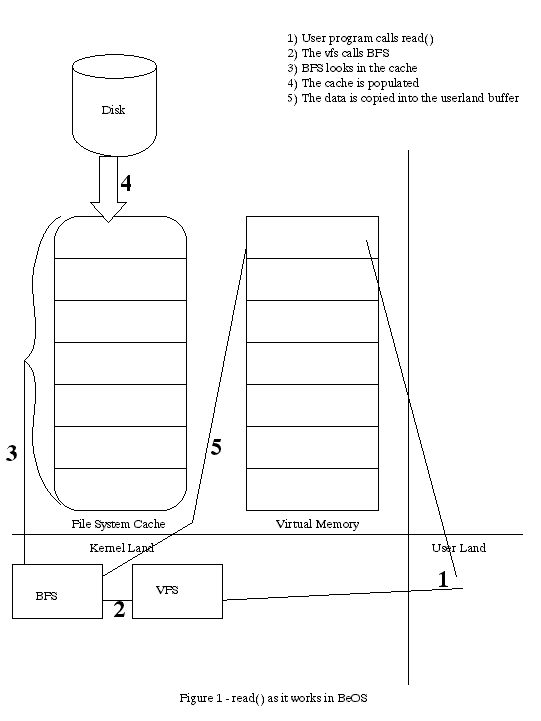
th (as per Practical File System Design, page 135). The disk block cache, if isolated from the VM system, is simpler in many regards. You keep a list of blocks that you have in the cache and pick some replacement algorithm (often times least recently used, or LRU). When a user requests a block, you check to see if you have it. If so, you update the block's reference date/time and return the block. If not, you pick the least recently used block, set its date/time to now, load the requested block into it, and return the block. See illustration 1. There are still some interesting pieces around journaling and read-ahead, though.
There are a few problems with this. One is that the amount of memory is fixed. The cache cannot grow or shrink as the system needs other memory. OK, well, we could fix this by adding a
shrink function and put a hook into the VM system that calls shrink when memory gets low. Maybe this shrink
would have a date/time--everything not referenced since that date/time would go away. Why, you may ask? Because it meshes well with most VM swapping routines--they check the "accessed" bit, which was cleared at some point in the past, and they clean out anything that has not been touched since then. Maybe you could even include a "desperation" level--maybe it doesn't make sense to get rid of *everything* prior to that date, if the system just barely needs more memory.
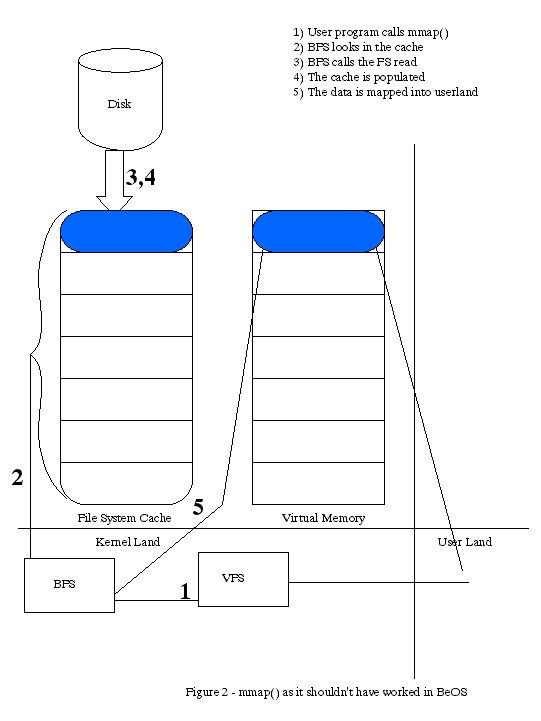
Another problem with this methodology is that it doesn't play well with mmap, which is why Be didn't implement mmap
, I believe. Let's take an example. You mmap some file (process A) which consists of 2 disk blocks of data. The VM system marks some address range as being "backed" by that file. You then read the first byte. The VM system faults (since that memory isn't really there). The VM system realizes that it needs to read that file. It calls the FS, which reads the block into the cache. It then returns that address to the VM system. Now, the VM system doesn't "own" the FS cache, so the VM has to allocate another page, copy the data from the FS cache to the VM-owned space. It then returns the new space to the calling process. But that data is in the system twice! See illustration 2.
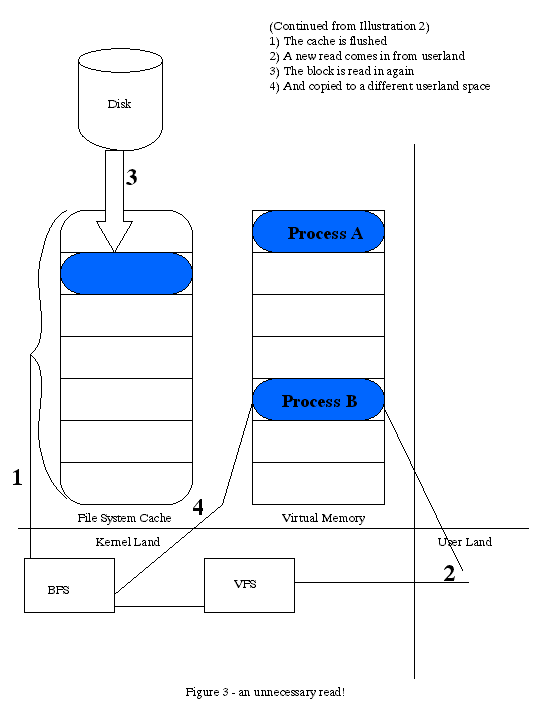
Furthermore, let's say that some heavy disk activity occurs and that cache block is released. Now some other process (process B)
mmaps that block. It is read in again, despite already existing in memory. This makes 3 copies in memory! See illustration 3.
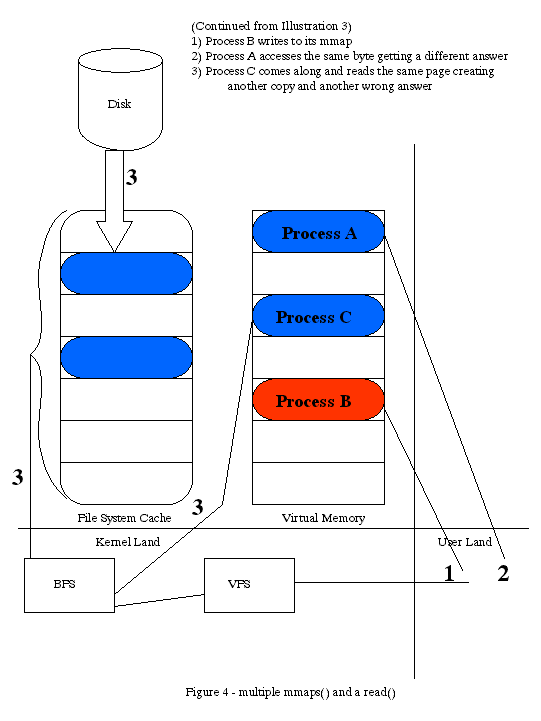
This is a wasted effort. To make the situation worse, process A writes to the block. Process B then reads the same byte. Unless the VM tracks all of the mappings, they don't know about each other. There is a bad race condition for applications which can be compounded by multiple apps reading/writing/
mmaping the same file. See illustration 4. One sidenote is the mmap has a parameter that allows you to avoid sharing of buffers between processes.
So, what do we do? My assertion is to let the VM do caching and virtual memory--this is similar to many other OSs out there. The concept is simple: Read and write work through the VM system. So when a
read() system call occurs, vm_read is called. The VM keeps track of every disk block that either is in memory or is virtual (i.e., mapped but not present). When
vm_read is called, the VM looks through the disk blocks. If it is not found, it is mapped into the cache's address space (which is part of kernel space, so it is limited to somewhere less than 2 GB). The VM then looks to see if the page is present. If so, it copies the data into the userland buffer (unavoidable, with the POSIX API) and returns. If the data is not present, it is handled in the same way as if the page was paged out. Right now, that is to load the page into an empty block of memory. Eventually, that will be to put this process on hold and notify the paging daemon that the block is needed. Write() works in a very similar way. An example is in illustration 5.
Eventually, though, these structures get full. Either the cache address-space gets full, or physical memory is expended. Cache space can be managed in many different ways. This is a classic replacement algorithm tradeoff--we can exchange processing time, memory and code complexity for some level of improvement of cache efficiency. This needs to be researched and explored in more detail. The other case is the more common one on all systems--physical memory is (nearly) all in use and some needs to be freed. My theory is that the VM system will iterate over the disk blocks that it knows about. Each disk block knows what virtual memory is mapped to it (a rough measure of how many processes could be effected by its being swapped out), how many of those mappings have been accessed since the last purging (a rough measure of how busy this block is), and whether or not the block has been written to (a rough measure of the cost of discarding it). It will produce a statistic from these on the "value" of that block to the system, then compare that value to the "desperation" of the system for memory. It will then decide whether to flush that memory or not.
|
|
|
|
It seems to me that Metcalfe's Law applies to file formats as much as it does to networks. Look at PDF as an example. It is a relatively new format, doesn't have the advantage of being supported out of the box by most OS's and fills a niche that is pretty small. The biggest reason that PDF has succeeded is that the reader is available for any system. Smaller file sizes and bookmarks are nice features, but really the key is that PDF was seen as a way to publish documents to the Web.
I was browsing Slashdot recently and one of the comments contained a link to openswf.org - an organization that holds the Shock Wave Flash standard. What? That is an open standard? I didn't know that. I starting thinking about the number of open standards that exist out there and about how lucky we (OpenBeOS) are.
It would be easy to complain about the non-open standards. Yes, .DOC, .XLS, .MDB, .PPT and a few others are out there and the open source community misses their presence a great deal. That aside, for a moment, the majority of data either can be or is, by default, saved to an open format. Bitmap formats are all open. I believe that most of the vector formats (Lightwave, Autocad and SVG) are open. Sound formats are all open, excepting the MP3 encoders. Many video formats are open, notable exceptions being Windows Media Format and some codecs for QuickTime. All of the OGG formats are open. RTF is an open format, something else that surprised me.
Rather than complaining about what is missing, though, I think that it would be more beneficial to adopt and praise the open standards. If open source projects don't support open standards, who will? Our apps need to go above and beyond commercial apps in our support of open standards. Make your RTF import/export perfect. Read and write every open format that you can get your hands on. Support those who open their design and ignore those who don't. Most of the time there is a way, albeit sometimes less than perfect, that every two applications can talk with each other.
BeOS has the Translation Kit, of course, to make loading images and text easier. The Media Kit handles sounds and video. Mike Wilber and I have talked (vaguely) about enhancing Translation Kit after R1 to make the Text format better, as well as incorporating Vector Graphics. Another format type for us to support is 3D vector formats.
Realistically, there is little standing between us (BeOS users) and the ability to read and write a lot more file formats. Some of them may be more useful than others, but Translators take little hard drive space and even less memory (when not in use). Translators are pretty easy to write, really, other than the complexity imposed by the file format itself. There are a lot of documents and file format help available on wotsit.org. Sure, there are tons of formats that are pretty obsolete or that we don't have established ways to convert. But there are plenty that we do, too. I looked at my translator directory - there are about 6 graphics and 1 text formats shipped with BeOS. I think that we can do a lot better than this.
Many of the same arguements apply to drivers. While there are a few drivers that will require work from the OBOS kernel team (USB, PCI, etc), the majority of drivers are waiting on one of three things: specs, a driver writer or the developer having the hardware. Take a look at: BeDrivers Most Wanted page. Lots of work that can be done there, too.
Since I have discussed all of the work that needs to be done, I need to give proper credit to those who have done or are doing the work. Marcus, Thomas, Bruno, Scott, Mike and all of the others, thank you. A great OS without drivers is a project for academia. Without you, BeOS would be dead, as would OpenBeOS.
|
|
|
|
|
|
|

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}