This page details how Haiku reads keys from the keyboard including modifier key and special characters, and how you can read and process these encoded characters in your application.
Haiku and UTF-8
Haiku encodes all characters using UTF-8. UTF-8 allows Haiku to represent characters from all over the world while still maintaining backwards compatibility with 7-bit ASCII codes. This means that the most commonly used characters are encoded in just one byte while less common characters can be encoded by extending the character encoding to use two, three, or, rarely, four bytes.
Key Codes
Each key on the keyboard is assigned a numeric code to identify it to the operating system. Most of the time you should not have to access these codes directly, instead use one of the constants defined in InterfaceDefs.h such B_BACKSPACE or B_ENTER or read the character from the key_map struct.
The following diagram shows the key codes as they appear on a US 104-key keyboard.
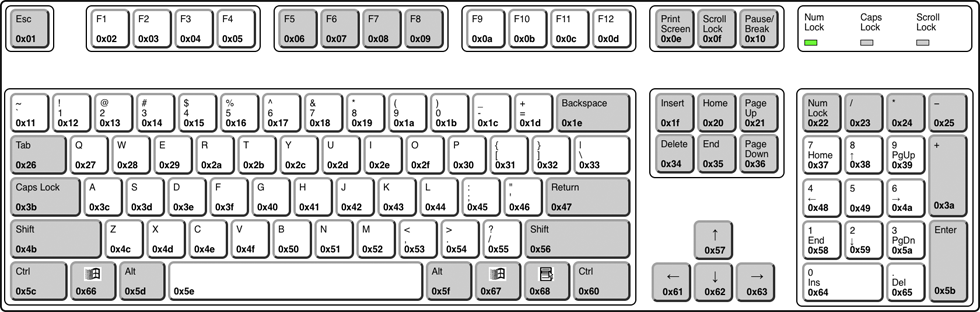
In addition to the keys listed in the picture above, some more keys are defined:
International keyboards each differ a bit but generally share an extra key located in-between the left shift key and Z with the key code 0x69.
Japanese keyboards also have a second extra key, either at the left of or under backspace. This second extra key gets the code 0x6b.
Mac keyboards have an equal sign in the keypad with key code 0x6a. Some other keys produce the same key code but appear in different locations than their PC counterparts.
BeOS used to allocate 0x6b to the power button on ADB keyboards. This is not the case in Haiku, instead, see the "multimedia" keys information below for the power button handling.
Some keyboards provide additional "multimedia" keys. These are reported based on their USB HID keycodes. Note that these codes are larger than 127, and therefore cannot be mapped in the keymap. These keys can only be handled using B_UNMAPPED_KEY_DOWN messages and are never associated with a character.
Here is a list of the commonly available key codes not visible in the keyboard picture above:
| Key code | Description |
|---|---|
| 0x69 | First extra international key |
| 0x6a | Numpad = |
| 0x6b | Second extra international key |
| 0x6c | Muhenkan (left of space bar on Japanese keyboards) |
| 0x6d | Henkan (first key right of spacebar on Japanese keyboards) |
| 0x6e | Katakana/Hiragana (second key right of spacebar on Japanese keyboards) |
| 0xf0 | Hangul key (for Korean keyboards) |
| 0xf1 | Hangul hanja key (for Korean keyboards) |
| 0x00010081 | Power off |
| 0x00010082 | Sleep |
| 0x00010083 | Wake up |
| 0x000C00B0 | Play media |
| 0x000C00B5 | Scan next track |
| 0x000C00B6 | Scan previous track |
| 0x000C00B7 | Stop media |
| 0x000C00E2 | Mute sound |
| 0x000C00E9 | Increase sound volume |
| 0x000C00EA | Decrease sound volume |
| 0x000C0183 | Launch control configuration application |
| 0x000C018A | Launch e-mail application |
| 0x000C0192 | Launch calculator application |
| 0x000C0194 | Launch file manager application |
| 0x000C0221 | Search |
| 0x000C0223 | Go to home page |
| 0x000C0224 | Previous page |
| 0x000C0225 | Next page |
| 0x000C0226 | Stop |
| 0x000C0227 | Refresh |
| 0x000C022A | Bookmarks |
Modifier Keys
Modifier keys are keys which have no effect on their own but when combined with another key modify the usual behavior of that key.
The following modifier keys are defined in InterfaceDefs.h
B_SHIFT_KEY | Transforms lowercase case characters into uppercase characters or chooses alternative punctuation characters. The shift key is also used in combination with B_COMMAND_KEY to produce keyboard shortcuts. |
B_COMMAND_KEY | Produces keyboard shortcuts for common operations such as cut, copy, paste, print, and find. |
B_CONTROL_KEY | Outputs control characters in terminal. The control key is sometimes also used as an alternative to B_COMMAND_KEY to produce keyboard shortcuts in applications. |
B_OPTION_KEY | Used to in combination with other keys to output special characters such as accented letters and symbols. Because B_OPTION_KEY is not found on all keyboards it should not be used for essential functions. |
B_MENU_KEY | The Menu key is used to produce contextual menus. Like B_OPTION_KEY, the Menu key should not be used for essential functions since it is not available on all keyboards. |
In addition you can access the left and right modifier keys individually with the following constants:
B_LEFT_SHIFT_KEY | B_RIGHT_SHIFT_KEY | B_LEFT_COMMAND_KEY | B_RIGHT_COMMAND_KEY |
B_LEFT_CONTROL_KEY | B_RIGHT_CONTROL_KEY | B_LEFT_OPTION_KEY | B_RIGHT_OPTION_KEY |
Scroll lock, num lock, and caps lock alter other keys pressed after they are released. They are defined by the following constants:
B_CAPS_LOCK | Produces uppercase characters. Reverses the effect of B_SHIFT_KEY for letters. |
B_SCROLL_LOCK | Prevents the terminal from scrolling. |
B_NUM_LOCK | Informs the numeric keypad to output numbers when on. Reverses the function of B_SHIFT_KEY for keys on the numeric keypad. |
To get the currently active modifiers use the modifiers() function defined in InterfaceDefs.h. This function returns a bitmap containing the currently active modifier keys. You can create a bit mask of the above constants to determine which modifiers are active.
Other Constants
The Interface Kit also defines constants for keys that are aren't represented by a symbol, these include:
B_BACKSPACE | B_RETURN | B_ENTER | B_SPACE | B_TAB | B_ESCAPE |
B_SUBSTITUTE | B_LEFT_ARROW | B_RIGHT_ARROW | B_UP_ARROW | B_DOWN_ARROW | B_INSERT |
B_DELETE | B_HOME | B_END | B_PAGE_UP | B_PAGE_DOWN | B_FUNCTION_KEY |
The B_FUNCTION_KEY constant can further be broken down into the following constants:
B_F1_KEY | B_F4_KEY | B_F7_KEY | B_F10_KEY | B_PRINT_KEY (Print Screen) |
B_F2_KEY | B_F5_KEY | B_F8_KEY | B_F11_KEY | B_SCROLL_KEY (Scroll Lock) |
B_F3_KEY | B_F6_KEY | B_F9_KEY | B_F12_KEY | B_PAUSE_KEY (Pause/Break) |
For Japanese keyboard two more constants are defined:
B_KATAKANA_HIRAGANAB_HANKAKU_ZENKAKU
The Keymap
The characters produced by each of the key codes is determined by the keymap. The usual way for the user to choose and modify their keymap is the Keymap preference application. A number of alternative keymaps such as dvorak and keymaps for different locales are available.
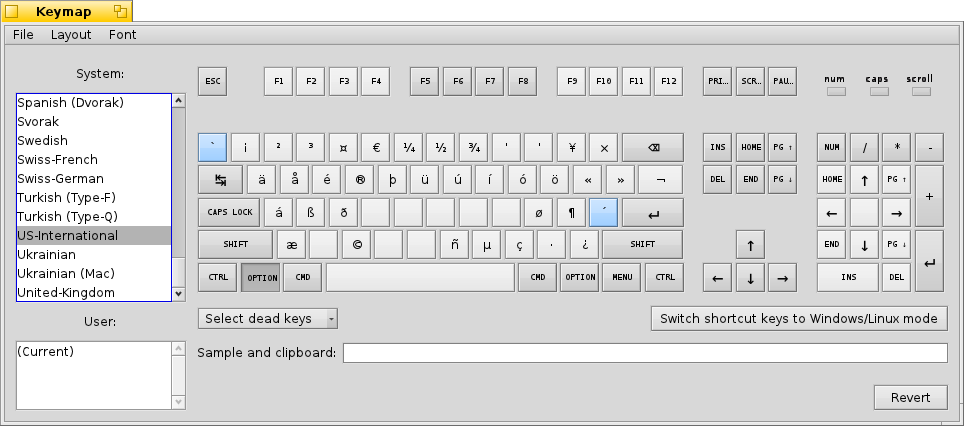
A full description of the Keymap preflet can be found in the User Guide.
The keymap is a map of the characters produced by each key on the keyboard including the characters produced when combined with the modifier constants described above. The keymap also contains the codes of the modifier keys and tables for dead keys.
To get the current system keymap create a pointer to a key_map struct and char array and pass their addresses to the get_key_map() function. The key_map struct will be filled out with the current system keymap and the char array will be filled out with the UTF-8 character encodings.
The key_map struct contains a number of fields. Each field is described in several sections below.
The first section contains a version number and the code assigned to each of the modifier keys.
version | The version number of the keymap |
caps_key scroll_key num_key | Lock key codes |
left_shift_key right_shift_key | Left and right shift key codes |
left_command_key right_command_key | Left and right command key codes |
left_control_key right_control_key | Left and right control key codes |
left_option_key right_option_key | Left and right option key codes |
menu_key | Menu key code |
lock_settings | A bitmap containing the default state of the lock keys |
To programmatically set a modifier key in the system keymap use the set_modifier_key() function. You can also programmatically set the state of the num lock, caps lock, and scroll lock keys by calling the set_keyboard_locks() function.
Character Maps
The next section of the key_map struct contains maps of offsets into the array of UTF-8 character encodings filled out in the second parameter of get_key_map(). Since the character maps are filled with UTF-8 characters they may be 1, 2, 3, or rarely 4 bytes long. The characters are contained in non-NUL terminated Pascal strings. The first byte of the string indicates how many bytes the character is made up of. For example the string for a horizontal ellipses (...) character looks like this:
The first byte is 03 meaning that the character is 3 bytes long. The remaining bytes E2 80 A6 are the UTF-8 byte representation of the horizontal ellipses character. Recall that there is no terminating NUL character for these strings.
Not every key is mapped to a character. If a key is unmapped the character array contains a 0-byte string. Unmapped keys do not produce B_KEY_DOWN messages.
Modifier keys should not be mapped into the character array.
The following character maps are defined:
control_map | Map of characters when the control key is pressed |
option_caps_shift_map | Map of characters when caps lock is turned on and both the option key and shift keys are pressed. |
option_caps_map | Map of characters when caps lock is turned on and the option key is pressed |
option_shift_map | Map of characters when both shift and option keys are pressed |
option_map | Map of characters when the option key is pressed |
caps_shift_map | Map of characters when caps lock is on and the shift key is pressed |
caps_map | Map of characters when caps lock is turned on |
shift_map | Map of characters when shift is pressed |
normal_map | Map of characters when no modifiers keys are pressed |
Dead Keys
Dead keys are keys that do not produce a character until they are combined with another key. Because these keys do not produce a character on their own they are considered "dead" until they are "brought to life" by being combined with another key. Dead keys are generally used to produce accented characters.
Each of the fields below is a 32-byte array of dead key characters. The dead keys are organized into pairs in the array. Each dead key array can contain up to 16 pairs of dead key characters. The first pair in the array should contain B_SPACE followed by and the accent character in the second offset. This serves to identify which accent character is contained in the array and serves to define a space followed by accent pair to represent the unadorned accent character.
The rest of the array is filled with pairs containing an unaccented character followed by the accent character.
acute_dead_key | Acute dead keys array |
grave_dead_key | Grave dead keys array |
circumflex_dead_key | Circumflex dead keys array |
dieresis_dead_key | Dieresis dead keys array |
tilde_dead_key | Tilde dead keys array |
The final section contains bitmaps that indicate which character table is used for each of the above dead keys. The bitmap can contain any of the following constants:
B_CONTROL_TABLEB_CAPS_SHIFT_TABLEB_OPTION_CAPS_SHIFT_TABLEB_CAPS_TABLEB_OPTION_CAPS_TABLEB_SHIFT_TABLEB_OPTION_SHIFT_TABLEB_NORMAL_TABLEB_OPTION_TABLE
The bitmaps often contain B_OPTION_TABLE because accent characters are generally produced by combining a letter with B_OPTION_KEY.
acute_tables | Acute dead keys table bitmap |
grave_tables | Grave dead keys table bitmap |
circumflex_tables | Circumflex dead keys table bitmap |
dieresis_tables | Dieresis dead keys table bitmap |
tilde_tables | Tilde dead keys table bitmap |